For the evalution of this year’s competition, we have established the training and test data sets, with published the full ground-truth for the validation and test sets. The complete dataset (validation + test) is publicly available at the following address: 必利勁
281/zenodo.3262372″>https://doi.org/10.5281/zenodo.3262372
The training set is described in S. Fiel, F. Kleber, M. Diem, V. Christlein, G. Louloudis, S. Nikos, and B. Gatos, “Icdar2017 competition on historical document writer identification (historical-wi),” in 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), vol. 01, Nov 2017, pp. 1377–1382.
The validation set encompasses 1200 images and the test set 20000 images.
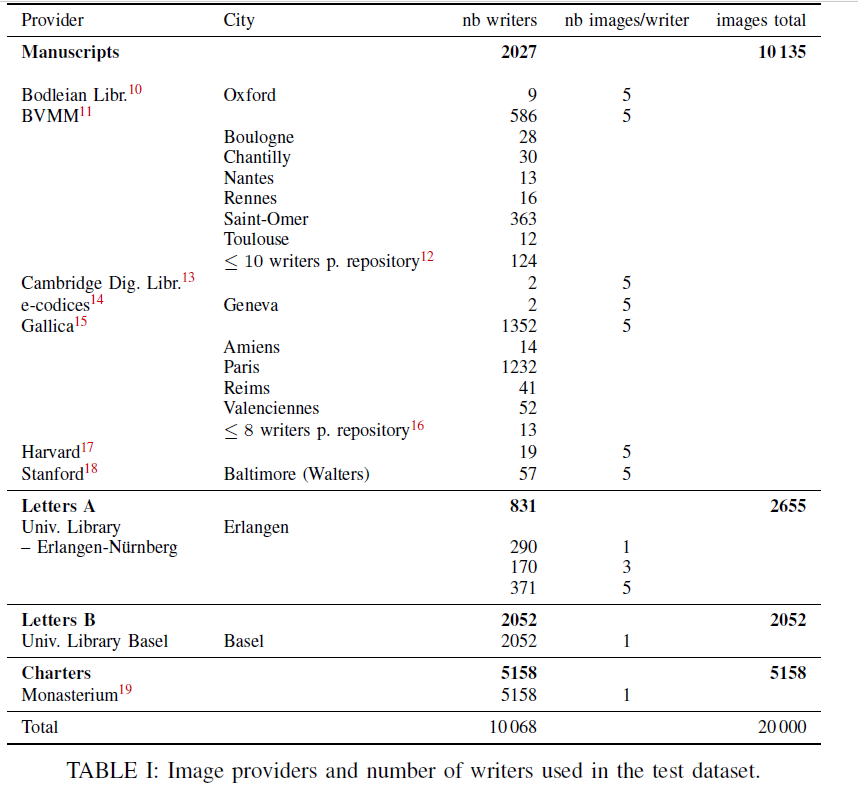
The provenance and distribution of the test set is as described in the following chart.
The test data set contains 20,000 images with different, i.e. 1-5 samples per writer . The corpus can be downloaded at the following link: 犀利士
href= »https://faubox.rrze.uni-erlangen.de/dl/fiCb7MhhW8nyM9Vy8d9KUxZu/wi_comp_19_test.zip »>https://faubox.rrze.uni-erlangen.de/dl/fiCb7MhhW8nyM9Vy8d9KUxZu/wi_comp_19_test.zip
The researchers and teams wishing to prepare the ICDAR-2019-HDRC-IR competition can now validate with an additional corpus. It encompasses handwritten letters as well as book scripts of the Middel Ages and 16th century.
We are glad to announce that this CLAMM website is hosting the announcemen犀利士5mg t and will host the data and results of a new competition for ICDAR2019, the ICDAR2019 Competition on Image Retrieva壯陽藥 l for Historical Handwritten Documents.
We merge our efforts of Writer identification and Script classification and create a new corpus! For more information, please click here (ICDAR-2019-HDRC-IR)
The tasks to be evaluated in the competition based on the CLaMM corpus (CLaMM : classification of Latin Medieval Manuscripts) are related to the classification of images of Latin Scripts, from handwritten books dated 500 C.E. to 1600 C.E.
Automated analysis and classification of handwritings applied to the written production of the European Middle Ages is a new challenge and a frontier in handwriting recognition and document analysis and recognition.
Context
Digital libraries from Cultural Heritage institutions contain literally ten-thousands of digitized manuscripts of the European Middle Ages. Some examples:
more than 12,000 fully digitized manuscripts in Manuscripta Mediaevalia (必利勁
uscripta-mediaevalia.de/ »>http://www.manuscripta-mediaevalia.de/);
10,000 in Gallica (http://gallica.bnf.fr), the digital library of the French National Library;
The overwhelming majority of manuscripts in there are written in Latin script.
In this context, there is a need for an automated “tagging” or “cataloguing” of the handwriting on the images, not only to allow for historical research (when and how which text is written), but primarily because it is a pre-requisite for handwritten text recognition (HTR) or automated indexing and data mining. To perform HTR on the digitized manuscripts, one “numerical model” is necessary to recognize the text for each script type and the identification of the script type is the first step.
This has been stated for the modern handwriting styles [1]. The medieval millennium extending from 500 C.E. to 1600 C.E. shows that the Latin script evolved and took very different forms, much more diverse than all the writing styles of the 19th to the 21st century.
3 Importance of the CLaMM dataset
The participants of this competition will get the only available reference data-set covering the European Middle Age and tagged as regards script types and production date.
In real-life conditions and beyond the challenges of material degradations, segmentation, etc., one of the difficulties is that there is a historical continuum in the evolution of scripts so that there are mixed types and many scripts that could pertain to two or more categories. In this regard, classification of scripts addresses the subjectivity of the human mind, so that, as in art history, all attributions remain subject to debate and discussion.
Related topics and previous work
The present competition on the Classification of Medieval Handwritings in Latin Script is related but differs from:
Segmentation and text detection on an image;
Binarization;
Image Feature Extraction;
Sorting out different scripts (Latin / Arabic / Greek / Hebrew, etc.);
Performing scribal identification within a homogenous corpus or within a particular manuscript.
The latter topic is the closest and has been dealt with by numerous competitions and publications [2]–[4].
As for the Classification of Medieval Handwritings in Latin Script specifically: the first attempt at automating the classification of medieval Latin scripts was made by the Graphem research project (Grapheme based Retrieval and Analysis for PalaeograpHic Expertise of medieval Manuscripts) funded by the French National Research Agency (ANR-07-MDCO-006, 2007-2011). The results are published in [5], [6].
Further research has been conducted on a theoretical level by one of the organizers and several teams in Computer Science[7]–[15]. Nevertheless none of the teams had access to the labelled data-set and the latter has not been made available anywhere.
Works Cited
[1] R. Niels and L. Vuurpijl, “Generating Copybooks from Consistent Handwriting Styles,” in Ninth International Conference on Document Analysis and Recognition, 2007. ICDAR 2007, 2007, vol. 2, pp. 1009–1013.
[2] L. R. B. Schomaker, K. Franke, and M. L. Bulacu, “Using codebooks of fragmented connected-component contours in forensic and historic writer identification,” Pattern Recognition Letters, vol. 28, no. 6, pp. 719–727, 2007.
[3] A. A. Brink, J. Smit, M. L. Bulacu, and L. R. B. Schomaker, “Writer identification using directional ink-trace width measurements,” Pattern Recognition, vol. 45, no. 1, pp. 162–171, 2012.
[4] S. He, M. Wiering, and L. R. B. Schomaker, “Junction detection in handwritten documents and its application to writer identification,” Pattern Recognition, vol. 48, pp. 4036–4048, 2015.
[5] D. Muzerelle and M. Gurrado, Eds., Analyse d’image et paléographie systématique : travaux du programme “Graphem” : communications présentées au colloque international “Paléographie fondamentale, paléographie expérimentale : l’écriture entre histoire et science” (Institut de recherche et d’histoire des textes (CNRS), Paris, 14-15 avril 2011). Paris: Association Gazette du livre médiéval, 2011.
[6] D. Stutzmann and M. Gurrado, “Mesure et histoire des écritures médiévales,” in Mesure et histoire médiévale, Actes du XLIIIe Congrès de la SHMESP, Paris: Publications de la Sorbonne, 2013, pp. 153–166.
[7] N. Vincent, A. Seropian, and G. Stamon, “Synthesis for handwriting analysis,” Pattern Recognition Letters, vol. 26, no. 3, pp. 267–275, 2005.
[8] G. Joutel, V. Eglin, and H. Emptoz, “Generic scale-space process for handwriting documents analysis,” in 19th International Conference on Pattern Recognition, 2008. ICPR 2008, 2008, pp. 1–4.
[9] I. Siddiqi, F. Cloppet, and N. Vincent, “Contour Based Features for the Classification of Ancient Manuscripts,” presented at the 14th Conference of the International Graphonolics Society, (IGS), Dijon, 2009.
[10] G. Joutel, V. Eglin, and H. Emptoz, “Generic Scale-Space Architecture for Handwriting Documents Analysis, chapter 15,” in Pattern Recognition Recent Advances, A. Herout, Ed. InTech, 2010, pp. 293–312.
[11] F. Cloppet, H. Daher, V. Églin, H. Emptoz, M. Exbrayat, G. Joutel, F. Lebourgeois, L. Martin, I. Moalla, I. Siddiqi, and N. Vincent, “New Tools for Exploring, Analysing and Categorising Medieval Scripts,” Digital Medievalist, no. 7, 2011.
[12] H. Daher, V. Églin, S. Brès, and N. Vincent, “Étude de la dynamique des écritures médiévales. Analyse et classification des formes écrites,” Gazette du livre médiéval, vol. 56–57, pp. 21–41, 2011.
[13] I. Siddiqi, F. Cloppet, and N. Vincent, “Writing property descriptors. A proposal for typological groupings,” Gazette du livre médiéval, vol. 56–57, pp. 42–57, 2011.
[14] V. Eglin, D. Gaceb, H. Daher, S. Bres, and N. Vincent, “Outils d’analyse de la dynamique des écritures médiévales pour l’aide à l’expertise paléographique,” Document Numérique, vol. 41, no. 1, pp. 81–104, 2011.
Nous utilisons des cookies pour vous garantir la meilleure expérience sur notre site. Si vous continuez à utiliser ce dernier, nous considérerons que vous acceptez l'utilisation des cookies.Ok