For the evalution of this year’s competition, we have established the training and test data sets, with published the full ground-truth for the validation and test sets. The complete dataset (validation + test) is publicly available at the following address: 必利勁 281/zenodo.3262372″>https://doi.org/10.5281/zenodo.3262372
The training set is described in S. Fiel, F. Kleber, M. Diem, V. Christlein, G. Louloudis, S. Nikos, and B. Gatos, “Icdar2017 competition on historical document writer identification (historical-wi),” in 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), vol. 01, Nov 2017, pp. 1377–1382.
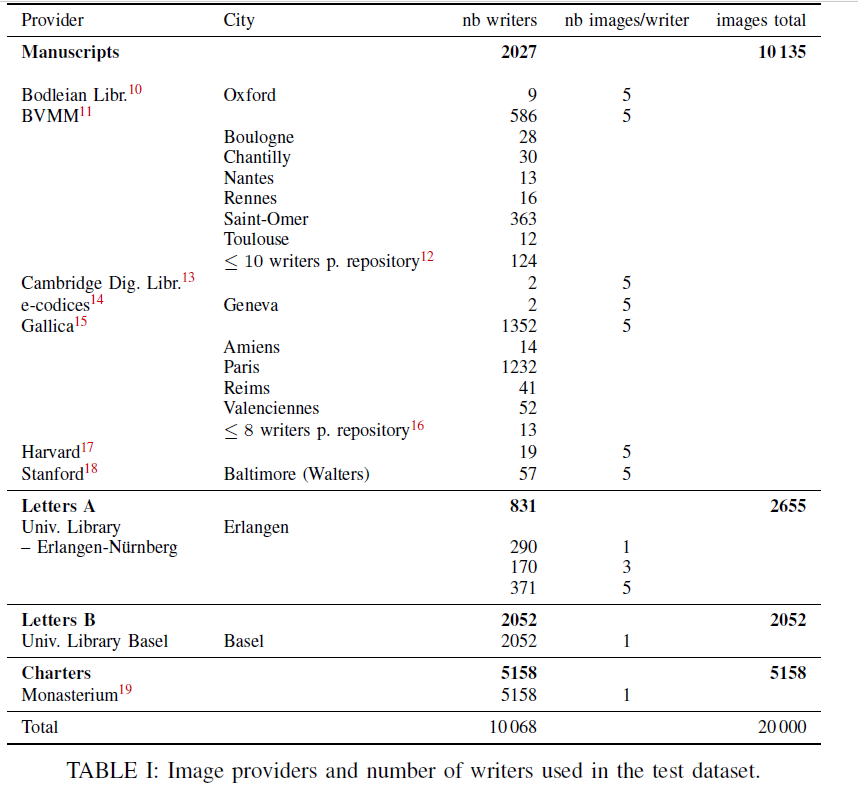
The validation set encompasses 1200 images and the test set 20000 images.
The provenance and distribution of the test set is as described in the following chart.